Building a scalable web application with ASP.NET Core and Azure - part 5

In this series of blog posts, we are going to build a scalable web application that can handle millions of users with Azure and .NET. In part 5, we’re going to look at some more advanced patterns and how we can use Azure Cosmos DB to implement them.
- Part 1 defines the scenario and requirements.
- Part 2 describes the initial implementation.
- Part 3 shows how we can test the scalability using Azure Load Testing and identify bottlenecks.
- Part 4 improves the scalability by implementing caching and relieving the load on the database.
We could still improve our current solution as described in part 3, and scaling up the database would be a viable option to improve performance as well at this point. However, we want to explore some other, a little more advanced techniques as well.
Sharding
In part 3, we proved that we can easily scale our application by deploying multiple instances to serve more requests. The database became the next bottleneck. At first sight, it doesn’t seem possible to apply the same solution here as well and divide the load between different servers - we can’t just duplicate our data and only update one randomly chosen copy on every write. We can, however, split the data by some known criteria and put the subsets into separate tables, databases, or even servers. This concept is known as sharding. For example, if you’re writing an e-commerce application, you don’t have to put all customers in the same storage location. You could split them by country, by the first letter of their name, by hashing their id, or whatever else fits your needs. The decision depends on how you need to query the data, and it is an important one, as this article on the Stack Overflow blog points out:
Your sharding strategy will significantly impact query efficiency and future scale-out.
…
The key points to consider when deciding how to shard a database are the characteristics of the business query and the data distribution.
Sharding with SQL Server
It is possible to implement sharding using relational databases, Azure even provides tools and documentation, and we could implement it for Scalection. It is, however, a bit involved and requires a lot of setup and manual steps, so we’ll do something else: We’re going to use a database that has sharding built in as a foundational concept: Cosmos DB.
Cosmos DB
What is Azure Cosmos DB? This question is surprisingly hard to answer. For years, the official definition by Microsoft was
Azure Cosmos DB is Microsoft’s globally distributed, massively scalable, horizontally partitioned, low latency, fully indexed, multi-model NoSql database.
That’s quite a mouthful, but Leonard Lobel has a good breakdown of what that actually means.
In recent years, Microsoft conglomerated even more technologies under the Cosmos DB label, including distributed relational Postgres databases and vector databases for AI applications. It seems that even Microsoft has given up providing a concise definition. The official documentation starts by listing various use cases for the different Cosmos DB flavors.
For our purposes, we can make do with the following (incomplete) definition:
Cosmos DB is a database system built for modern web and mobile applications. It offers virtually unlimited scale via horizontal partitioning and guaranteed throughput by provisioning the necessary resources up front.
As described in the article linked above, you can use Cosmos DB as a NoSql database in a variety of ways (document, graph, key-value, column). We’re going to use it for storing JSON documents for our entities (parties, voters, etc).
Horizontal partitioning refers to the built-in sharding: Apart from an id, every document also needs to have a partition key that determines its storage location when the data is distributed. Cosmos DB automatically shards (or partitions) the data based on this key.
Provisioned throughput
In part 3, we noticed that calls to the relational database got slower with an increasing number of concurrent requests, making it hard to predict the actual latency for a given number of users. Cosmos DB follows a different strategy here as well: It offers “single-digit millisecond response times along with guaranteed speed at any scale.” How is that possible? You need to tell it how much throughput you’re going to need using request units:
A Request unit is a performance currency abstracting the system resources such as CPU, IOPS, and memory that are required to perform the database operations supported by Azure Cosmos DB. Whether the database operation is a write, point read, or query, operations are always measured in RUs. For example, a point read (fetching a single item by its ID and partition key value) for a 1-KB item is one Request Unit (or one RU).
The database then ensures that it has enough capacity to provide the guarantees mentioned above. When you try to consume more request units than you provisioned, the database simply returns an error (HTTP status 429: Too many requests) instead of trying to keep up. This might sound dramatic, but for a scalable application, it’s actually better than getting slower and slower until it eventually breaks.
Also, it forces developers to think about their performance requirements up front, which is also a good thing.
It is still possible to use auto-scaling (within a range of 10x the configured throughput).
Modeling data
Another difference between NoSql and relational databases is how you think about data: In relational databases, you try to normalize the data in order to avoid duplication and the schema is very important, it’s what defines your model. In NoSql databases, you try to optimize for easy read access. It’s okay to denormalize data so that you don’t need to join different tables together.
This causes some other problems of course, you need other strategies to avoid inconsistencies. It’s always a tradeoff.
You can go even further and put different entities in the same container, even if their schema is completely different (it’s just JSON, after all). This can make sense if they are often read together.
In relational databases, you combine data with the same schema in a table, so you usually have one table per entity. In NoSql databases, you can can put all kinds of entities in the same container if they have the same partition key. For example, if you’re building a CRM application, you could store e-mails, notes, telephone calls, etc. in the same container and use the customer id as a partition key. That way, you could show a timeline of the communication with a given customer with a single query that only needs to load data from a single partition (i.e., one physical location).
We can only scratch the surface here, but the documentation provides useful samples and guides for data modeling.
Using Cosmos DB in Scalection
For Scalection, we create two containers to hold our data: One for elections and parties (partitioned by ElectionId) and one for election districts, voters and votes (partitioned by ElectionDistrictId).
Data model
Cosmos DB documents need a unique id property and - as we want to use sharding - also a partition key. Any property can be used as partition key. Since we want to put entities of different types in the same container, we’re also going to store the type and use a concatenation of type and the entity id as unique id. This allows us to store voters and election districts in the same container, even though they both use numeric ids:
{
"id": "ElectionDistrict-1",
"name": "District 00001",
"electionId": "af555808-063a-4eeb-9eb2-77090a2bff42",
"electionDistrictId": 1,
"partitionKey": "af555808-063a-4eeb-9eb2-77090a2bff42/1",
"type": "ElectionDistrict",
"_rid": "MdIGAN2Hn14LAAAAAAAAAA==",
"_self": "dbs/MdIGAA==/colls/MdIGAN2Hn14=/docs/MdIGAN2Hn14LAAAAAAAAAA==/",
"_etag": "\"7d004f3f-0000-1500-0000-66751bbb0000\"",
"_attachments": "attachments/",
"_ts": 1718950843
}
{
"voterId": 1,
"id": "Voter-1",
"voted": true,
"electionId": "af555808-063a-4eeb-9eb2-77090a2bff42",
"electionDistrictId": 2,
"partitionKey": "af555808-063a-4eeb-9eb2-77090a2bff42/2",
"type": "Voter",
"_rid": "MdIGAN2Hn14SJwAAAAAAAA==",
"_self": "dbs/MdIGAA==/colls/MdIGAN2Hn14=/docs/MdIGAN2Hn14SJwAAAAAAAA==/",
"_etag": "\"0b00f0b5-0000-1500-0000-66840b6a0000\"",
"_attachments": "attachments/",
"_ts": 1719929706
}
The properties starting with _ are system properties and are added automatically.
Here’s the representation of the Voter entity in C#.
public class Voter : ElectionDistrictEntity
{
public long VoterId { get; set; }
public override string Id => CreateId(VoterId);
public bool Voted { get; set; }
}
It relies on two base classes for defining the id and partition key.
Here's the code if you're interested in the details.
// Base class for all entities partitioned by the election district
public abstract class ElectionDistrictEntity : CosmosEntity
{
public Guid ElectionId { get; set; }
public long ElectionDistrictId { get; set; }
public string PartitionKey =>
CreatePartitionKey(ElectionId, ElectionDistrictId);
public static string CreatePartitionKey(Guid electionId, long electionDistrictId) =>
$"{electionId}/{electionDistrictId}";
}
// Base class for all entities
public abstract class CosmosEntity
{
public abstract string Id { get; }
public string Type => GetName(GetType());
public string CreateId(object id) => CreateId(GetType(), id);
public static string CreateId<TEntity>(object id)
where TEntity : CosmosEntity => CreateId(typeof(TEntity), id);
public static string GetName<TEntity>()
where TEntity : CosmosEntity => GetName(typeof(TEntity));
private static string CreateId(Type t, object id) =>
$"{GetName(t)}-{id}";
private static string GetName(Type t) => t.Name;
}
Since we’re now storing data as documents and not in tables, we can also embed candidates directly in the parties. There’s a finite amount of candidates per party, we don’t need to read or write them independently, and it can save one read operation:
{
"partyId": "c77948df2-a387-5efd-936a-9324a753c6e1",
"id": "Party-c77948df2-a387-5efd-936a-9324a753c6e1",
"electionId": "af555808-063a-4eeb-9eb2-77090a2bff42",
"name": "Team Tabs",
"candidates": [
{
"candidateId": "2996fe75-3a54-5bc8-b00b-3701cb494331",
"name": "Brian Kernighan"
},
{
"candidateId": "504c1141-ee13-52fd-ac5c-f32bfe31cca6",
"name": "Dennis Ritchie"
},
...
],
"type": "Party",
"_rid": "MdIGAJqg0XgCAAAAAAAAAA==",
"_self": "dbs/MdIGAA==/colls/MdIGAJqg0Xg=/docs/MdIGAJqg0XgCAAAAAAAAAA==/",
"_etag": "\"000087e4-0000-1500-0000-66751bba0000\"",
"_attachments": "attachments/",
"_ts": 1718950842
}
You can find all the entity and base classes on GitHub.
API implementation
While it would be possible to access a Cosmos DB using EF Core, we’re going to use the Cosmos SDK directly. We can use LINQ as well for queries, and with some custom extension methods, the code looks very similar to the EF Core data access:
app.MapGet(
"election/{electionId:guid}/party",
(CosmosClient client, Guid electionId, CancellationToken ct) =>
{
return client.Parties()
.Where(p => p.ElectionId == electionId)
.Select(p => new
{
p.PartyId,
p.Name,
Candidates = p.Candidates.Select(c => new
{
c.CandidateId,
c.Name
})
}).ToAsyncEnumerable(cancellationToken);
}).CacheOutput();
For the POST Vote endpoint, we only need one read operation for the validation because we embedded the candidates into the parties:
var party = await cache.GetOrCreateAsync(
$"Party_{dto.PartyId}",
async cacheEntry =>
{
cacheEntry.AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(8);
try
{
var partyResponse = await client
.ElectionContainer()
.ReadItemAsync<Party>(
CosmosEntity.CreateId<Party>(dto.PartyId),
new PartitionKey(electionId.ToString()));
return partyResponse.Resource;
}
catch (CosmosException e) when (e.StatusCode == HttpStatusCode.NotFound)
{
return null;
}
});
if (party == null || party.ElectionId != electionId)
{
return Results.NotFound();
}
if (dto.CandidateId.HasValue)
{
if (!party.Candidates.Any(c => c.CandidateId == dto.CandidateId))
{
return Results.NotFound();
}
}
Unfortunately, the SDK throws an exception when we try to read a non-existant item instead of returning null, which makes the code a little more complicated than it should be.
Next, we try to read the voter and check if he hasn’t already voted:
var cosmosVoterId = CosmosEntity.CreateId<Voter>(voterId);
var partitionKey = new PartitionKey(
ElectionDistrictEntity.CreatePartitionKey(electionId, electionDistrictId));
var electionDistrictContainer = client.ElectionDistrictContainer();
ItemResponse<Voter> voterResponse;
try
{
voterResponse = await electionDistrictContainer.ReadItemAsync<Voter>(
cosmosVoterId,
partitionKey,
cancellationToken: cancellationToken);
}
catch (CosmosException e) when (e.StatusCode == HttpStatusCode.NotFound)
{
return Results.Unauthorized();
}
if (voterResponse.Resource.Voted)
{
return Results.Conflict();
}
This time we store the whole response the SDK returns which contains the actual Voter entity (in the Resource property), but also some metadata which we are going to use shortly.
Transactions and concurrency
In our original implementation, we used a transaction with an isolation level of RepeatableRead to avoid race conditions, which boils down to a lock on the row in the database. This is also referred to as “pessimistic concurrency control”, as we assume there’s going to be a conflict and take precautions accordingly, accepting the negative consequences.
“Optimistic concurrency control”, on the other hand, assumes that in the common case there’s not going to be a conflict and so we want to avoid a performance penalty in that case. Instead, we want the update to fail if the data has been modified in the meantime.
Optimistic concurrency control is not limited to Cosmos DB, you can also implement it with relational databases. As with partitioning, Cosmos DB offers it as a built-in capability though: The response returned from the read operation above contains an ETag property which we can include in the update:
Every item stored in an Azure Cosmos DB container has a system defined
_etagproperty. The value of the_etagis automatically generated and updated by the server every time the item is updated._etagcan be used with the client suppliedif-matchrequest header to allow the server to decide whether an item can be conditionally updated. The value of theif-matchheader matches the value of the_etagat the server, the item is then updated. If the value of theif-matchrequest header is no longer current, the server rejects the operation with an “HTTP 412 Precondition failure” response message.
var transaction = electionDistrictContainer.CreateTransactionalBatch(partitionKey);
transaction.CreateItem(new Vote()
{
VoteId = Guid.NewGuid(),
ElectionId = electionId,
PartyId = dto.PartyId,
CandidateId = dto.CandidateId,
ElectionDistrictId = electionDistrictId,
Timestamp = DateTime.UtcNow
});
transaction.PatchItem(
cosmosVoterId,
[PatchOperation.Set("/voted", true)],
new()
{
IfMatchEtag = voterResponse.ETag
});
var response = await transaction.ExecuteAsync(cancellationToken);
return response.IsSuccessStatusCode
? Results.NoContent()
: Results.Conflict();
We create a TransactionalBatch in order to create the Vote and update the Voted flag in an atomic operation. For the update, we include the ETag we read before. Because of this, the whole batch will only succeed if the voter has not been modified in the meantime, so we can be sure that the Voted flag is still false.
Multi-item transaction are only supported within the same partition, but that’s not a problem for us since the Vote and Voter both live in the same partition (determined by the ElectionDistrictId).
Feel free to examine the whole code on GitHub.
Local development
We also extended the Aspire app host and the migration service so that it can also be used to initialize the Cosmos database.
In order to run the projects locally, you need to provision a Cosmos DB in Azure (we included the .bicep files in the repo). Microsoft provides a Cosmos DB emulator for local development, but unfortunately it’s rather unstable causes more trouble than it solves.
Provisioning throughput
As mentioned above, Cosmos DB can only provide latency and throughput guarantees if we provision how many request units we need. So, how much do we need? There’s a capacity planner tool that can be used to estimate the required RU/s, but as we already have some working code, we can simply try it out: Every Cosmos DB operation returns the amount of request units it consumed.
We don’t need to reserve any resources for the GET Parties requests thanks to the output caching.
For POST Vote, we have two database operations (parties and candidates are also cached after the first request):
- Reading the voter: 1 RU
- Creating the vote and updating the voter in the transactional batch: 19.93 RU
So each POST Vote request consumes about 21 RU. In order to support 5,500 of those requests per second, we need to provision at least 115,500 RU/s (we increased the value a bit during the load test just to be safe).
Load test
Now we’re able to run a final load test. Here are the results (green) compared to the previous version with (pink) and without (purple) caching:
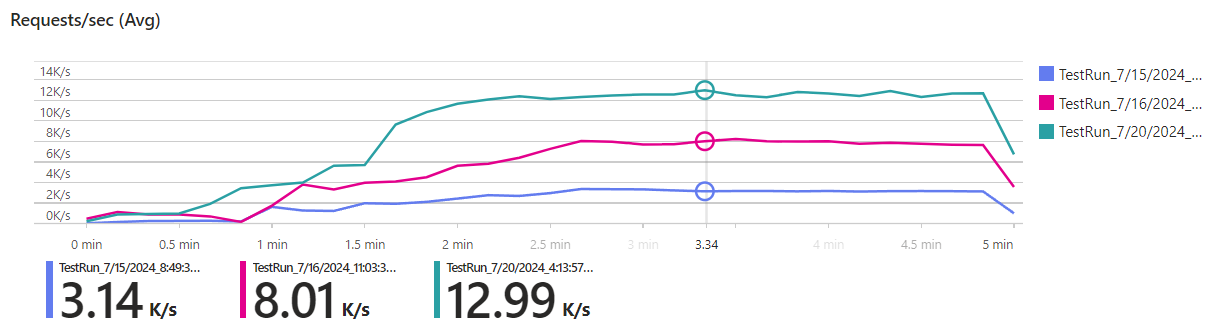
Mission accomplished! Our goal was to handle 11k requests per second, but we even surpassed it with 13k requests per second.
We can also see that the average response time is not only a lot lower, but also more stable:
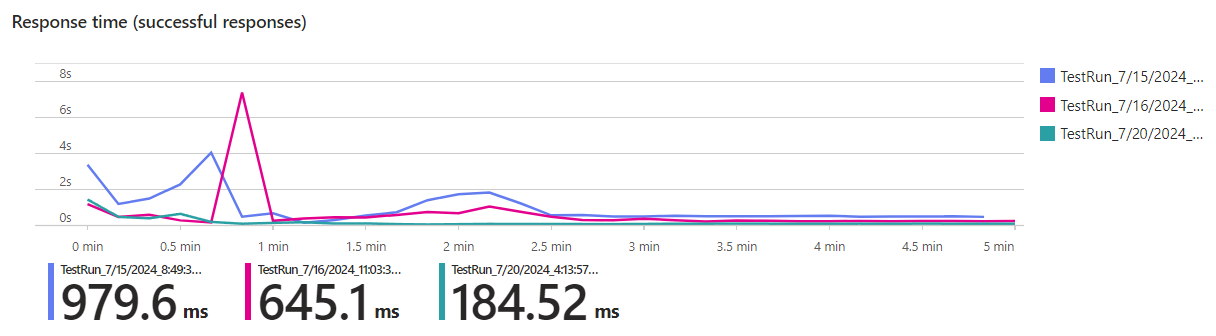
Summary
This was a rather long post, but had to cover a lot of ground: We introduced Cosmos DB and how it can offer guaranteed latency and throughput, talked about the differences in data modeling for NoSql databases and established optimistic concurrency control. Then we applied it all to our Scalection app and verified that we now reach the scalability goal we set back in the first post. Feel free to dive into the code on GitHub or proceed to the final post of this series for a summary of our journey.