Building a scalable web application with ASP.NET Core and Azure - part 4

In this series of blog posts, we are going to build a scalable web application that can handle millions of users with Azure and .NET. In part 4, we’re going to implement a caching mechanism and measure the improvements.
- Part 1 defines the scenario and requirements.
- Part 2 describes the initial implementation.
- Part 3 shows how we can test the scalability using Azure Load Testing and identify bottlenecks.
Implementing caching to reduce the load on the database
In the last post, we identified the database as our current bottleneck. One way to reduce the load is to avoid unnecessary calls by caching the results. Only the first time data is requested, we actually load it from the database. Then we keep it in memory and future requests can directly return it. On the one hand, this speeds up the requests because we don’t need a roundtrip over the network. On the other hand, this relieves the database so it can use its resources for other requests. It sounds like a win-win situation, but, as usual, there’s a catch: How do you know if the data you cached is still up-to-date? When someone modifies the original data, we need to throw away our cached copies and reload it, so that we don’t keep returning the outdated version to the clients. This is known as cache invalidation and it’s known to be a notoriously difficult problem: There are many variations of the following quote:
There are only two hard things in Computer Science: cache invalidation and naming things.
There are different solutions to this problem, all with different advantages and drawbacks, but we are lucky: In our Scalection app, most of the data doesn’t change at all during the election day! Parties, candidates and election districts are all static data we can load once and keep until the end of the election.
Caching in ASP.NET Core
ASP.NET Core offers multiple caching mechanisms for different use cases:
-
In-memory caching uses server memory to store cached data. This is useful for storing arbitrary data across requests. Accessing the cache is very fast, but you need to be careful when there are multiple server instances: Each instance has its own, private cache.
-
Distributed caching uses a shared cache in an external process that can be accessed by all instances. You can use different implementations like Redis or NCache. It’s slower than in-memory caching as the shared cache needs to be accessed over the network, but usually still much faster than a database, and you can avoid consistency problems because all instances see the same data.
-
Hybrid caching combines in-memory and distributed caching. If the data is not found in the in-memory cache, it is retrieved from the distributed cache, and only if it’s not found there either it is loaded from the original source.
-
Output caching caches the HTTP responses for certain requests on the server. If another request to the same URL is received, the processing is skipped and the cached response is returned instead. Because of this, output caching can only work for
GETorHEADrequests that don’t modify data, but it’s very easy to implement as you don’t need to modify the request handler. All you need to do is decorate the endpoint to instruct ASP.NET to cache the responses. You can combine output caching with distributed caching to share the cached responses across app instances. -
Response caching sounds similar to output caching, but it works differently. It uses the HTTP caching headers to instruct the client if and how it should cache responses. It can be used to tell browsers not to reload images on every visit to a page, for example. As it only works to avoid duplicate requests from the same client, it’s not a good fit for our scalability problem.
Caching in Scalection
Which of these mechanisms should we use for Scalection? As mentioned above, output caching is very easy to implement.
Output caching for GET Parties
We need to register the necessary services:
builder.Services.AddOutputCache(options =>
{
options.AddBasePolicy(builder => builder.Expire(TimeSpan.FromHours(8)));
});
The base policy can be used to define some default values, here we set the expiration time (how long the responses should be cached?) to eight hours. These values can be overridden per endpoint though.
Next we need to add the output caching middleware:
app.UseOutputCache();
Finally, we decorate the GET Parties endpoint:
app.MapGet("election/{electionId:guid}/party",
async (ScalectionContext context, Guid electionId, CancellationToken ct) =>
{
...
}).CacheOutput(); // enable output caching for this endpoint
That’s it. No need to modify the implementation of the endpoint.
In-memory caching for POST Vote
For the POST Vote endpoint, we can’t use output caching as we can’t just skip the whole processing - we need to store the vote in the database. What we can do is store the parties and candidates in an in-memory cache so that we don’t need to load them from the database every time.
Again, we need to register the necessary services:
builder.Services.AddMemoryCache();
This allows us to inject an IMemoryCache into the request handler:
app.MapPost(
"election/{electionId:guid}/vote",
async (
[FromHeader(Name = "x-election-district-id")] long electionDistrictId,
[FromHeader(Name = "x-voter-id")] long voterId,
Guid electionId,
VoteDto dto,
ScalectionContext context,
IMemoryCache cache, // inject the memory cache
CancellationToken ct) =>
{
...
});
We can then use its GetOrCreateAsync method to retrieve data with a given key from the cache. This method will simply return the value from the cache if the given key is found. If not, the factory we pass will be called to produce a value. The factory is passed an ICacheEntry it can use to specify the lifetime and its return value is added to the cache. In any case, the data will be present in the cache after GetOrCreateAsync is called and will be returned to the caller:
var party = await cache.GetOrCreateAsync(
$"Party_{dto.PartyId}", // the cache key
async cacheEntry => // factory, only called if the key is not found
{
// load the party from the database and cache for 8 hours
cacheEntry.AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(8);
return await context.Parties.FindAsync(dto.PartyId);
});
if (party == null || party.ElectionId != electionId)
{
return Results.NotFound();
}
We can do the same for candidates as well:
if (dto.CandidateId.HasValue)
{
var candidate = await cache.GetOrCreateAsync(
$"Candidate_{dto.CandidateId}_{dto.PartyId}",
async cacheEntry =>
{
cacheEntry.AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(8);
return await context.Candidates.SingleOrDefaultAsync(
c => c.CandidateId == dto.CandidateId && c.PartyId == dto.PartyId);
});
if (candidate == null)
{
return Results.NotFound();
}
}
The rest of the method (storing the vote, etc.) can remain unchanged.
You can find the whole implementation in the v2-caching branch on GitHub.
We added it as a separate service so that we can run both versions in parallel.
Should we use a distributed or hybrid cache?
We only use per-instance in-memory caching for the POST Vote endpoint, meaning that each instance has its own cache. The amount of data we need to cache isn’t a problem, the in-memory cache is faster and we don’t need to pay for an external cache service. Since our data doesn’t change at all, we don’t have any consistency problems between the instances, so using a distributed cache wouldn’t have any benefits in our case.
We don’t expect that many voters try to vote multiple times (it wouldn’t work since we set the Voted flag). If that were the case, we could improve performance by keeping the voters in a cache as well. This, however, would be a situation where we would need to use a distributed or hybrid cache in order to avoid inconsistencies.
Load test with caching
Now that we’re finished with the implementation, let’s see if it improved the scalability. Here’s the result of another test run, this time with our caching improvements:
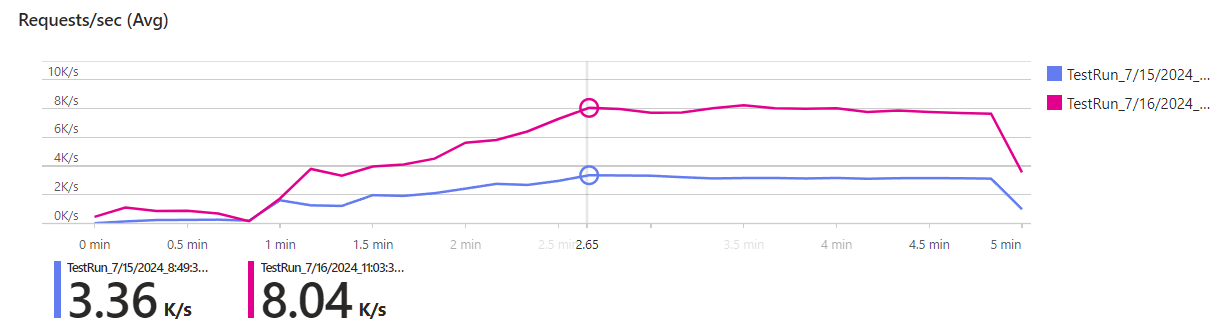
The purple line shows the throughput without caching, the pink line with caching. With just a few lines of code, we more than doubled the throughput to 8k requests per second!
The database’s CPU consumption remains pretty much the same:
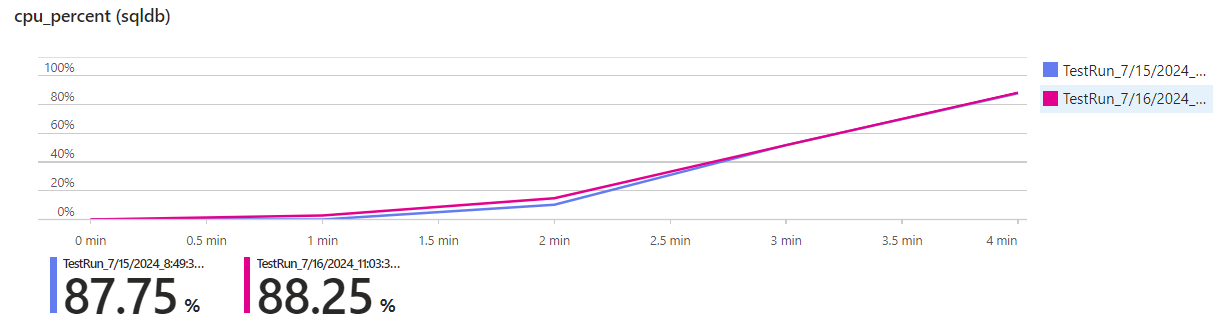
But now all of the CPU time is used for storing the votes instead of reading the parties and candidates over and over again, which is why we can serve so many more requests.
Using only minor code changes, we made a huge step towards our goal of 11k requests per second, but we’re not quite there yet. In the next post, we’re going to explore some more advanced options.
Summary
Caching can dramatically increase an app’s throughput and performance by reusing previous results instead of repeatedly calculating or retrieving them. This speeds up these requests while freeing resources to do other tasks.
Granted, our sample provided optimal conditions because of the “immutable” data. Preventing cached data from getting stale can be a challenge, but nearly every app has at least some potential for quick wins using the different caching techniques mentioned above. It is a vital technique for building scalable applications.