Machine Learning in der Cloud? Teil 3: MNIST-Klassifizierung

Machine Learning in der Cloud - in dieser Blogserie demonstriere ich, wie ein Modell zur Ziffern-Klassifizierung mithilfe von Azure Machine Learning trainiert und produktiv eingesetzt werden kann. Mit dem erarbeiteten Wissen aus den vorherigen Beiträgen werden wir uns in diesem Blogeintrag damit beschäftigen, ein Klassifizierungsmodell für das MNIST-Datenset zu trainieren. Das erhaltene Modell wird danach veröffentlicht und über eine HTTP-Schnittstelle getestet.
Um dir eine lange Bilderdokumentation des Azure-Portals aus 2023 zu ersparen, habe ich fünf Python-Skripte vorbereitet. Diese kümmern sich sowohl um Training, Deployment und Testen des Modells als auch um das Erstellen und schlussendliche Entfernen der dafür notwendigen Azure-Ressourcen.
Vorbereitung
Um die Skripte auszuführen, benötigst du (1) die Azure CLI und (2) Python in Version 3.9. Die Installationsanleitung zur Azure CLI ist hier zu finden und Python kann hier über den Microsoft-Store installiert werden. Danach folge bitte diesen Schritten:
- Lade die Python-Skripte hier herunter und entpacke die ZIP-Datei.
- Öffne Powershell und führe den Befehl
az loginaus, um dich in der Azure CLI mit deinem Microsoft-Konto anzumelden. - Um die Skripte ausführen zu können, müssen noch deren Abhängigkeiten installiert werden. Anstatt diese global zu installieren, solltest du diese mithilfe von
venvgekapselt in einer virtuellen Umgebung installieren. Führe dafür die folgenden Befehle im Schritt 1 entpackten ZIP-Ordner auf gleicher Ebene wie demsrc-Ordner aus.
# Erstellt eine neue virtuelle Python-Umgebung
python3 -m venv ./venv
# Aktiviert die virtuelle Umgebung
.\venv\Scripts\activate
# Aktualisiert pip, wheel und setuptools
python -m pip install --upgrade pip
pip install --upgrade wheel setuptools
# Installiert die Skript-Dependencies
pip install -r requirements.txt
Azure Ressourcen vorbereiten
Bevor wir mit Azure ML arbeiten können, müssen wir zuerst einmal mehrere Azure-Ressourcen mit dem 1_resource_creator.py-Skript erstellen.
Keine Angst: Bevor das Skript beginnt, Ressourcen zu erstellen, wirst du gefragt, in welcher Subscription diese angelegt werden sollen. Die angelegten Ressourcen werden innerhalb einer neuen Resource Group gruppiert und können daher einfach wieder gelöscht werden. Die einzige Änderung außerhalb der Resource Group ist die Erstellung einer neuen App Registration, damit die folgenden Skripte mit Azure ML interagieren können. Um alle Aktionen auf Azure rückgängig zu machen, findest du eine Anleitung am Ende dieses Posts bei Ressourcen löschen.
Aber welche Ressourcen werden überhaupt erstellt und konfiguriert?
rg-azure-ml-showcase-xxxxxxxx [Resource Group]
├── mlw-mlshowcase-xxxxxxxx [Azure Machine Learning Workspace]
| ├── Application Insights
| ├── Container Registry
| ├── Key Vault
| ├── Log Analytics Workspace
| └── Storage Account
└── id-compute-cluster [Managed Identity]
Active Directory
└── ar-aml-showcase-client-xxxxxxxx [App Registration]
Die hierarchisch unter dem Azure Machine Learning Workspace aufgelisteten Ressourcen sind dafür notwendig, um diesen betreiben zu können und werden von Azure automatisch erstellt. Die Managed Identity wird unserem Compute Cluster zugewiesen, damit dieser später auf den Storage Account zugreifen kann. Die App Registration im Active Directory wird von den folgenden Skripten verwendet, um auf den Azure ML Workspace Zugriff zu haben.
Außerdem konfiguriert das Skript in Azure ML Studio …
- … das Train und Test-Set des MNIST-Datensets, …
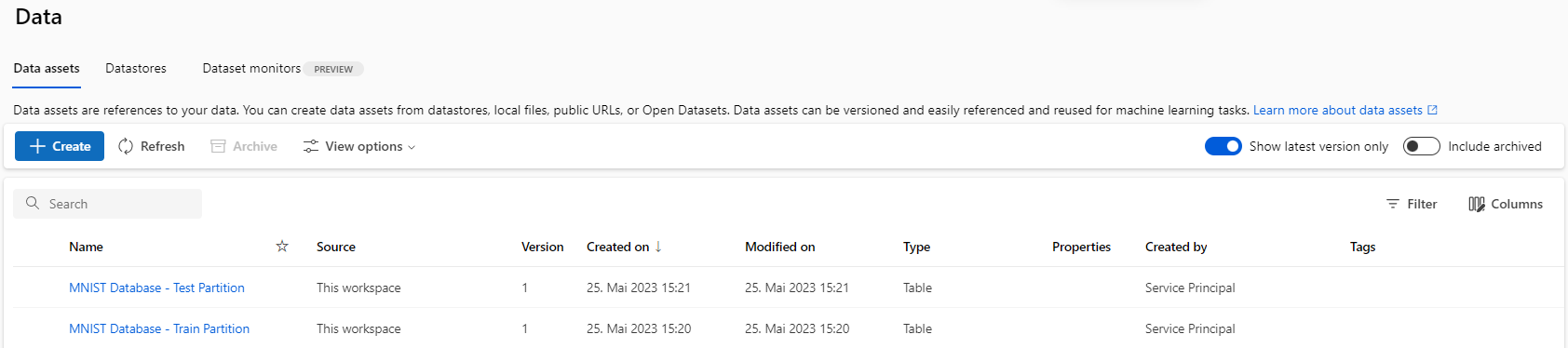
- … einen Compute Cluster für das spätere Training und …

- … ein Environment (Docker Image) in dem der Trainings-Prozess ausgeführt wird.
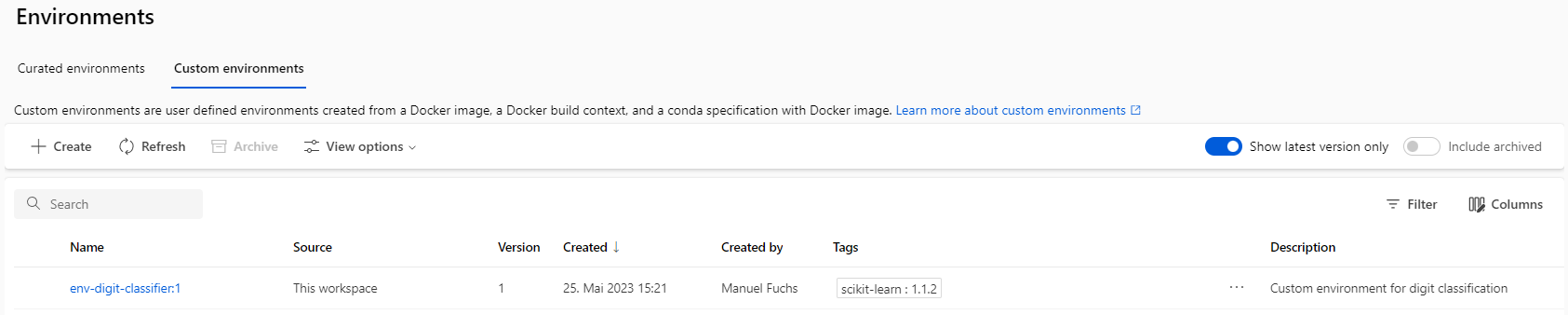
Die mit Azure Resource Manager (ARM) und Bicep vertrauten Leser:innen werden an dieser Stelle in leichtes Stirnrunzeln verfallen, denn diese Microsoft Werkzeuge hätten auch theoretisch zur Ressourcenerstellung genutzt werden können. Wieso dann ein Python-Skript?
Grund dafür ist, dass nicht alles über diese Microsoft Tools umsetzbar gewesen wäre, z.B. die Einrichtung des MNIST-Datensets in Azure ML. Da exakt definiert ist, welche Stichproben im Test- oder Train-Set landen sollen, ist mehr Logik dafür erforderlich. Bevor du jetzt aber blindlings die Skripte ausführst, kannst du gerne den Quelltext lesen.
Um das Skript auszuführen, führe folgende Befehle aus. Wie zuvor solltest du die Befehle innerhalb des entpackten Skript-Ordners ausführen:
# Aktiviert die virtuelle Umgebung
.\venv\Scripts\activate
# Startet die Ressourcen-Erstellung
python .\src\1_resource_creator.py
Nachdem das Skript ausgeführt wurde, kannst du dir im Azure Portal und im Azure ML Studio Interface das Ergebnis ansehen.
Modell trainieren
Mit den eingerichteten Azure-Ressourcen können wir nun unser Modell zur Ziffernklassifizierung mit dem 2_training.py trainieren. Führe dazu mit den folgenden Befehlen das 2_training_scheduler.py-Skript aus, um das Training-Skript über einen Azure ML Job auf dem Cluster auszuführen, ohne deine eigene Hardware dafür zu strapazieren:
# Aktiviert die virtuelle Umgebung
.\venv\Scripts\activate
# Erstellt einen neuen Azure ML Job
python .\src\2_training_scheduler.py
Aber was genau passiert im Trainings-Skript? Grob zusammengefasst besteht dieses aus diesen vier Schritten:
- Daten laden und vorverarbeiten: Zuerst werden das Trainings- und Test-Set des MNIST-Datensets von Azure ML geladen und für das Training vorverarbeitet.
- Modell trainieren: Es werden mehrere Modelle trainiert und anschließend wird mithilfe von Cross-Validation das am besten geeignete auf dem Trainings-Set gewählt.
- Modell evaluieren: Die Vorhersageleistung des besten Modells wird anhand mehrerer Metriken auf dem Test-Set ausgewertet.
- Modell exportieren: Das Modell wird mit dem Namen
digit-classifiernach Azure ML exportiert.
Im Azure ML Studio Interface kannst du dir den aktuellen Fortschritt des Trainings-Skripts unter Jobs > train_digit_classifier_model > Digit Classifier Model Training ansehen. Auf der Overview-Seite sind einige von Azure ML automatisch erkannte Metadaten aufgelistet - vom Namen der eingesetzten Modell-Implementierung bis hin zu getesten Modell-Parametern. Sobald das Skript fertig ist, kann auf der Images-Seite die Modell-Vorhersageleistung auf dem Test-Set visualisiert werden. Diese wird durch eine Confusion Matrix veranschaulicht - einer Evaluierungsmethode für Klassifizierung. Ich bekam ich folgendes Ergebnis:
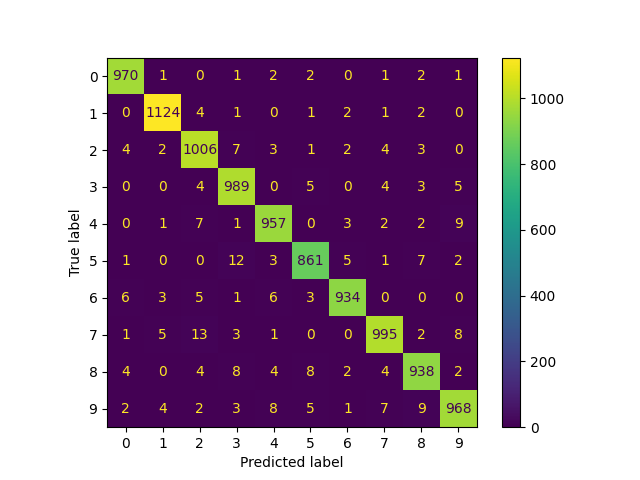
In einer Confusion Matrix werden zeilen- und spaltenweise die Klassen (bei uns
0bis9) aufgetragen, wobei Spalten die Modell-Vorhersagen und Zeilen die tatsächliche Klasse der Stichproben beschreiben. In einer Matrix-Zelle, z.B.( x=2, y=7 ), befindet sich dann die Summe der Stichproben, die vom Modell als Ziffer2klassifiziert wurden, aber tatsächlich eine7abbilden (diese Verwechslung ist meinem Modell13mal passiert). Somit beschreiben die Zellen in der Diagonale die korrekten Vorhersagen. Und je größer / kleiner die Summe in einer Zelle ist, desto heller / dunkler wird diese eingefärbt.
Als nächsten Schritt müssten wir die Confusion Matrix nun genauer analysieren, um die Modell-Tauglichkeit für einen Produktiveinsatz zu bestimmen. Beispielsweise könnten wir versuchen, die 13-Verwechslungen zwischen 7 und 2 weiter zu reduzieren, andere Modell-Arten oder -Parameter testen - dies würde aber an dieser Stelle den Rahmen sprengen. Wir nehmen daher an dieser Stelle an, dass das erhaltene Modell ausreichend gute Ergebnisse für unsere Zwecke liefert.
Modell deployen und verwenden
Wir sind nun fast soweit, unsere Ziffernerkennung produktiv einsetzen können. Was uns dafür noch fehlt, sind ein Azure ML Endpoint, der eine HTTP-Schnittstelle für Stichproben anbietet und diese an ein Azure ML Deployment weiterleitet, in dem das exportierte Modell ausgeführt wird. Um Endpoint und Deployment zu erstellen, führe das 3_deployment.py-Skript wie folgt aus:
# Aktiviert die virtuelle Umgebung
.\venv\Scripts\activate
# Erstellt einen neuen Endpoint mit dem neuen Modell
python .\src\3_deployment.py
Für Fortgeschrittene: Da wir ein
sklearn-Modell trainiert haben und Azure ML diese und weitere Python-Bibliotheken gut unterstützt, muss nicht einmal der Boilerplate-Code geschrieben werden, wie die Daten vom Endpoint an das Modell übergeben werden - Azure ML kann diesen automatisch generieren.
Nachdem der Endpoint und dessen Deployment fertig erstellt wurden, sollten wir deren Funktionsweise auch testen. Um neue Stichproben zu simulieren, können wir wieder das Test-Set verwenden, da dieses keinen Einfluss auf Modell-Training und -Auswahl hatte. Das vorbereitete Skript 4_test_client.py nimmt die ersten 20 Stichproben des Test-Sets, verarbeitet diese vor, sendet sie an den Endpunkt und gibt die returnierten Vorhersagen auf die Konsole aus.
# Aktiviert die virtuelle Umgebung
.\venv\Scripts\activate
# Erstellt einen neuen Endpoint mit dem neuen Modell
python .\src\4_test_client.py
Mein trainiertes Modell konnte fehlerfrei die ersten 20 Ziffern des Test-Sets erkennen:
┌───────┬────────────┐
│ Label │ Prediction │
├───────┼────────────┤
│ 7 │ 7 │ ✅
│ 2 │ 2 │ ✅
│ 1 │ 1 │ ✅
│ 0 │ 0 │ ✅
│ 4 │ 4 │ ✅
│ 1 │ 1 │ ✅
│ 4 │ 4 │ ✅
│ 9 │ 9 │ ✅
│ 5 │ 5 │ ✅
│ 9 │ 9 │ ✅
│ 0 │ 0 │ ✅
│ 6 │ 6 │ ✅
│ 9 │ 9 │ ✅
│ 0 │ 0 │ ✅
│ 1 │ 1 │ ✅
│ 5 │ 5 │ ✅
│ 9 │ 9 │ ✅
│ 7 │ 7 │ ✅
│ 3 │ 3 │ ✅
│ 4 │ 4 │ ✅
└───────┴────────────┘
Ressourcen löschen
Um die durch die Skripte erstellten Azure-Ressourcen wieder zu entfernen, kannst du das Skript 5_cleanup.py mit folgenden Schritten ausführen. Damit wird die erstellte Ressourcengruppe rg-azure-ml-showcase-xxxxxxxx gelöscht und die im Active Directory erstellte App Registration ar-aml-showcase-client-xxxxxxxx. Außerdem wird die Azure CLI ML Extension entfernt, falls diese zuvor noch nicht installiert war.
# Aktiviert die virtuelle Umgebung
.\venv\Scripts\activate
# Erstellt einen neuen Endpoint mit dem neuen Modell
python .\src\5_cleanup.py
Schlussworte
Zusammenfassend lässt sich festhalten, dass Azure Machine Learning Studio eine mächtige Plattform für beliebige ML-Aufgabenstellungen ist. Dank der leistungsstarken Azure Hardware konnten wir in unserem Beispiel das Ziffernklassifizierungs-Modell schnell trainieren, ohne dabei auf eigene Hardware angewiesen zu sein. Bei komplexeren Problemen muss man sich daher auch keine Gedanken über den Erwerb und die Verwaltung leistungsfähigerer Hardware machen. Außerdem konnten wir durch Einsatz von Endpoints und deren gute Modell-Integration die Modell-Veröffentlichung beinahe automatisch lösen.
Darüber hinaus bietet Azure Machine Learning Studio noch weitere Funktionen, zum Beispiel Auto ML. Dadurch können Modelle automatisch trainiert und optimiert werden und es bleibt somit mehr Zeit, die Ergebnisse zu evaluieren. Die Plattform bietet außerdem auch Unterstützung bei Data Labeling und Responsible Building.
Obwohl wir Python für die Umsetzung unseres Modells verwendet haben, ist es auch wichtig zu betonen, dass Azure Machine Learning Studio technologieunabhängig ist. Da der eigene Code in Containern ausgeführt wird, können beliebige Technologien und Frameworks genutzt werden.
Wenn du an der Nutzung von Azure Machine Learning interessiert bist oder weitere Fragen dazu hast, kannst du mich gerne kontaktieren. Auch das Team von softaware steht dir gerne zur Verfügung, um gemeinsam aus deinen individuellen Anforderungen innovative Lösungen zu entwickeln.
Ressourcen: