ML in der Cloud? Teil 2: AML Konzepte

Machine Learning in der Cloud - in dieser Blogserie demonstriere ich, wie ein Modell zur Ziffern-Klassifizierung mithilfe von Azure Machine Learning trainiert und produktiv eingesetzt werden kann. In diesem Artikel werden wir neben dem später eingesetzten Datenset auch die Terminologie und Konzepte von Azure Machine Learning kennenlernen.
Azure Machine Learning - Big Picture
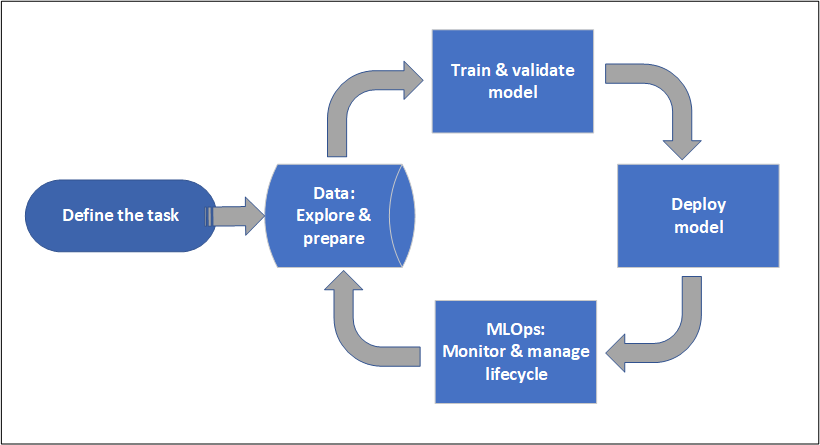
Um die Frage “Was ist Azure Machine Learning überhaupt und was kann man damit umsetzen?” endlich zu beantworten: Azure ML ist ein SaaS-Produkt von Azure, mit dem man den gesamten Lebenzyklus eines Machine Learning Projektes abbilden kann. Ein solcher Lebenszyklus kann mehrere Personen involvieren und grob in folgende Schritte eingeteilt werden:

Der erste Schritt in einem ML-Projekt ist zu definieren, welche Frage vom Modell überhaupt beantwortet werden soll. Nachdem das Problem definiert wurde, sollte man sich mit dem verwendeten Datenset vertraut machen und - falls möglich - die Datenqualität durch Vorverarbeitung (pre-processing) verbessern. Anschließend werden Modelle trainiert, evaluiert und das Geeignetste ausgewählt. Dieses Modell wird dann produktiv eingesetzt. Sobald dieses erste Modell auf neue Stichproben trifft, ist es wichtig, dessen Verhalten zu überwachen, bzw. ein besser geeignetes Modell mithilfe der neu gewonnen Daten zu trainineren. Dieser letzte Schritt wird oft als MLOps bezeichnet.
Datenset zur Ziffernklassifizierung - Die MNIST-Datenbank
Ziel dieser Blogserie ist es, ein Modell zu erzeugen, das hangeschriebene Ziffern in einem Bild erkennen kann. Dies ist ein Klassifizierungsproblem, bei dem die vorherzusagenden Klassen die Ziffern von 0 bis 9 sind. Damit wir aber überhaupt ein Modell trainieren können, brauchen wir zuerst ein Datenset mit Beispieldaten, von denen unser Modell lernen kann.
Als Ziffernklassifizierungs-Datenset werden wir die MNIST-Datenbank verwenden. Das M in MNIST steht für modified, da dieses aus zwei Datensets der NIST besteht. Beide Datensets beinhalten zwar Bilder von handgeschriebenen Ziffern, jedoch sind die Ziffern in einem Datenset schwerer erkennbar als in dem anderen. Um eine ähnliche Schwierigkeit im Train- und Test-Set zu gewährleisten, wurde die MNIST-Datenbank bereits im Vorhinein auf diese aufgeteilt. In diesem Train- und Test-Set werden gleich viele Stichproben aus beiden zugrundeliegenden Datensets verwendet. Das Train-Set besteht aus 60.000 Stichproben, während das Test-Set 10.000 Stichproben umfasst. Die Bilder selbst sind 28x28 Pixel groß und die aufgenommene Ziffer befindet sich zentriert im Mittelpunkt. Im Folgenden sind sechs Stichproben visualisiert:
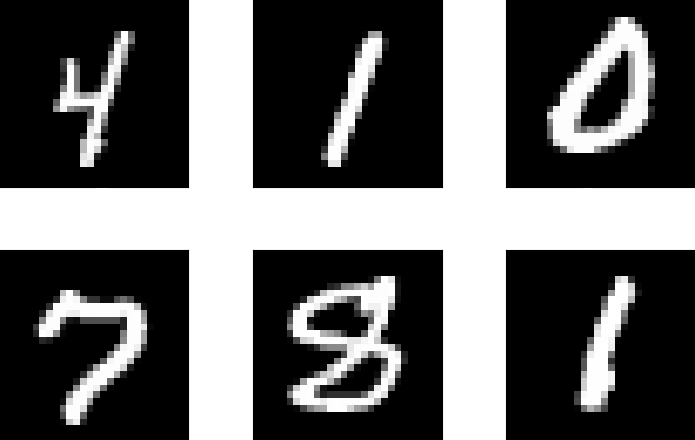
Azure Machine Learning - Terminologie
Data Assets
Um die MNIST-Datenbank in Azure ML verfügbar zu machen, können wir diese als sogenanntes Data Asset registrieren. Datensets werden nicht direkt in Azure ML gespeichert, sondern lediglich von externen Quellen gelesen. Da die Daten nicht dupliziert werden, entstehen keine zusätzlichen Speicherkosten. Der große Vorteil von Data Assets ist, dass Azure ML eine einheitliche Schnittstelle zu diesen anbietet, unabhängig vom tatsächlichen Speicherort und Medium. Zusätzlich können diese versioniert werden und unterstützen folgende Speichermedien als Quelle:
- Azure Data Lake (Gen. 1 & 2)
- Azure Blog Storage
- Azure Files
- Öffentlich erreichbare URLs
Wie wir die MNIST-Datenbank als Data Asset in Azure ML registrieren, werden wir im nächsten Blogartikel behandeln.
Compute Instances
Damit wir die registrierten Data Assets aber auch verwenden können, benötigen wir Hardware-Ressourcen. Wir könnten unser Modell zur Ziffernklassifizierung zwar lokal trainieren, jedoch stößt man bei schwieriger zu lösenden ML-Problemen schnell an die Grenzen der eigenen Hardware. Anstatt jetzt nach neuer Ausstattung für die hauseigene Serverfarm zu suchen, ist es oft kosteneffizienter, diese Hardware bei einem Cloud-Anbieter für kurze Zeit zu mieten. Dies ist über Azure ML Compute Instances möglich.
Compute Instances sind in Azure ML registrierte Hardware-Ressourcen, auf denen verschiedenste Aufgaben ausgeführt werden können. Wir werden im folgenden Blogartikel unser Ziffern-Klassifizierungsmodell auch auf einer Compute Instance trainieren. Ähnlich zu Data Assets abstrahieren Compute Instances die Interaktion mit der zugrundeliegenden Hardware. Die folgenden Ressourcen-Arten können als Compute Instance verwendet werden:
- Virtual Machines
- Compute Cluster
- Azure Kubernetes Service
- Attached Compute Resources (Azure Databricks, Data Lake Analytics, …)
Compute Cluster sind eine gute Wahl, wenn man keine gleichbleibende Auslastung der Hardware erwartet. Je nach Bedarf kann der Cluster die Menge an virtuellen Maschinen verringern oder erhöhen, um Kosten zu sparen.
Jobs und Experiments
Wenn wir nun ein Modell auf einer Compute Instance trainieren würden, würde man diese eine Trainingsausführung als Job bezeichnen. Azure ML Jobs werden zusätzlich in sogenannten Experiments gebündelt. Experiments dienen rein der Organisation von Jobs und sind daher sehr nützlich, wenn verschiedene Job-Arten regelmäßig ausgeführt werden.
Environments
Damit wir aber unsere ML-Prozesse als Jobs ausführen können, benötigen wir nicht nur Compute Instances, sondern auch eine Möglichkeit, Software-Abhängigkeiten zu installieren. Anstatt an einem Powershell-Script herumbasteln zu müssen, das uns eine Laufzeitumgebung konfiguriert, können wir zum Glück ein bestehendes Konzept in Azure ML nutzen - Containerisierung. Dadurch kann Azure ML einen Job in einer isolierten Sandbox laufen lassen, die alle Dependencies dieses Prozesses beinhaltet, dem sogenanten Container. Diese Container werden aus Azure ML Environments erstellt, welche nichts anderes als OCI Images sind.
Models
Da wir endlich ein ML-Modell in einem Job trainieren können, stellt sich nun die Frage, was mit dem erlangten ML-Modell nach dem Job passieren soll. Um die erlangten Modell-Einstellungen nicht zu verlieren, müssen diese gespeichert werden. Genau dafür können Azure ML Models genutzt werden.
Endpoints und Deployments
Um das Model schlussendlich einzusetzen, können Azure ML Endpoints und Deployments genutzt werden. Mit Endpoints können Anwender:innen über eine HTTP-Schnittstelle anfordern, dass das Modell auf neue Stichproben schließen soll. Sobald ein solcher Request bei einem Endpoint eingeht, leitet dieser die Daten an ein dahinterliegendes Deployment weiter. Deployments hosten eine konkrete Azure ML Model Version und kümmern sich um die Schlussfolgerung aus Stichproben. Je nach Anforderungen an den Endpoint kann man sich zwischen den folgenden Varianten entscheiden:
- Realtime-Endpoints (auch Online-Endpoints) werden dazu eingesetzt, um in Echtzeit auf wenige Stichproben zu schließen. Die Stichproben werden dafür in der Request-Payload übergeben.
- Batch-Endpoints schließen asynchron auf sehr große Datenmengen. In der Request-Payload befindet sich lediglich ein Zeiger auf den Speicherort der Stichproben, das dahinterliegende Deployment muss diese anschließend selbst laden.
Zusammenfassung
Azure Machine Learning ist ein Tool, mit dem der gesamte Lebenszyklus einer ML-Anwendung abgebildet werden kann. Datensets können als Data Assets registriert und einzelne Skript-Ausführungen als Job abgebildet werden, welche durch Experiments gruppiert werden. Ein Job wird auf den Ressourcen einer Compute Instance und innerhalb eines Environments ausgeführt, das alle Dependencies des Jobs umfasst. Ein durch einen Job erhaltenes ML-Modell kann dann als Model in Azure ML registriert werden. Um ein Model einsetzen zu können, stellen Endpoints dieses den Anwendern über einen HTTP-Endpunkt zur Verfügung. Endpoints leiten diesen Request schlussendlich an ein Deployment weiter, dass das Model hostet und darüber aus den Stichproben schließen kann.
Da wir nun das notwendige Wissen zu Machine Learning und Azure ML besitzen, können wir uns im nächsten Blogartikel mit dem Ziffernklassifizierungsproblem praktisch auseinandersetzen.
Quellen und Verweise:
{kind=link}